Project Overview
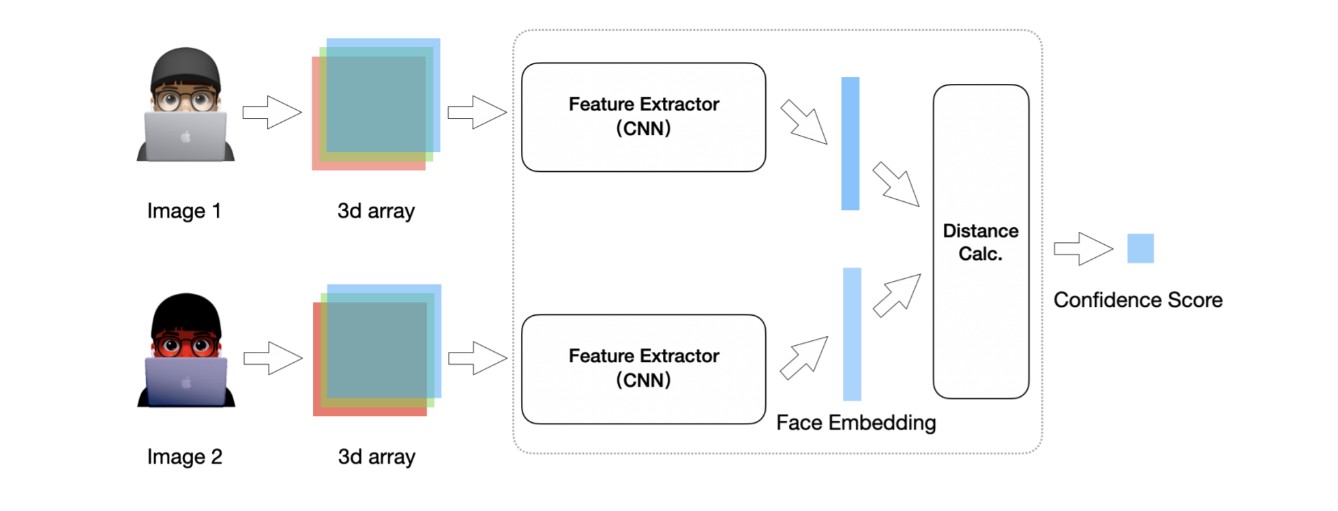
This project focused on developing a convolutional neural network (CNN) system capable of performing both face classification and verification tasks. By training a deep learning model to extract discriminative facial features, I created a system that could not only identify faces from a closed set of known identities but also verify whether two previously unseen faces belonged to the same person.
Core Technical Challenges
- Designing an efficient CNN architecture for extracting meaningful facial features
- Implementing specialized loss functions to improve feature discrimination
- Creating a verification pipeline that could compare facial embeddings effectively
- Optimizing the model for both closed-set classification and open-set verification
Technologies Used
- PyTorch
- Weights & Biases (for experiment tracking)
- Kaggle (competition platform)
- Image processing libraries (Torchvision)
- CUDA/GPU acceleration
Dataset and Problem Structure
The project utilized a subset of the VGGFace2 dataset, consisting of 8,631 different identities with substantial variation in pose, age, illumination, ethnicity, and other attributes. The dataset was divided into two main components:
- Classification dataset: Used for model training with labeled identities
- Verification dataset: Used for validation and testing, containing 6,000 image pairs with 5,749 unique identities
This structure created an interesting challenge: the model needed to learn generalizable facial features from the classification task that would transfer effectively to the verification task, where many identities would be entirely new to the system.
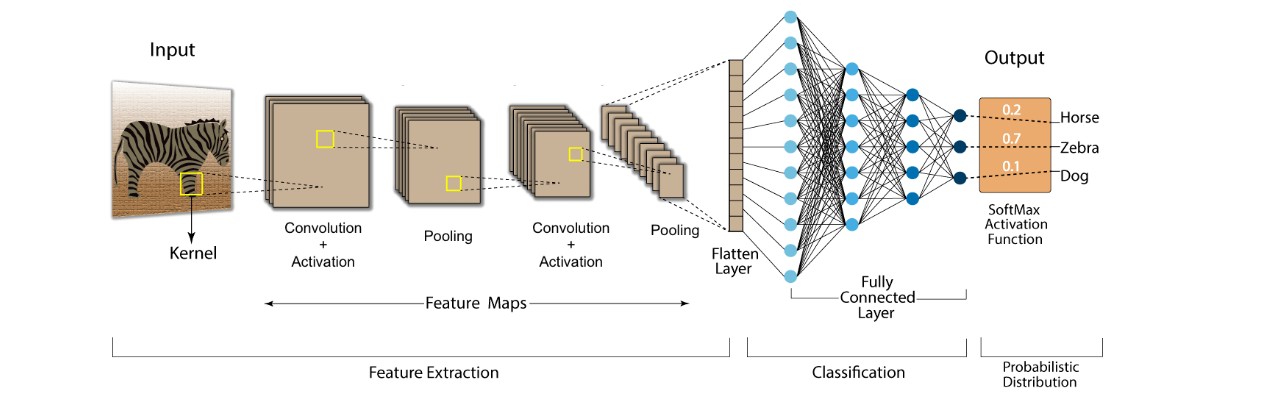
CNN Architecture Design
After experimenting with several architectural patterns, I implemented a ResNet-inspired model with specialized components:
Network Architecture:
- Feature extraction backbone with residual connections
- Three residual blocks with skip connections
- Squeeze-and-Excitation attention mechanism
- Global pooling and feature normalization
- Classification layer (used only during training)The inclusion of residual connections was crucial for training deeper networks effectively, helping to mitigate the vanishing gradient problem that typically plagues deep CNNs.
Key Architectural Components
- Residual Blocks: Enabled learning deeper representations by allowing gradient flow through skip connections
- Squeeze-and-Excitation Module: Applied channel attention to enhance important feature channels and suppress less useful ones
- Normalization Layers: Applied batch normalization after each convolutional layer to stabilize training
- Global Pooling: Reduced spatial dimensions to create a fixed-length feature vector (embedding)
- Feature Normalization: Ensured that feature vectors had unit norm for consistent similarity calculation
Loss Function Engineering
One of the most fascinating aspects of this project was exploring how different loss functions affected the learned feature space:
Cross-Entropy Loss Limitations
Initially, I implemented standard cross-entropy (CE) loss for the classification task. While effective for closed-set recognition, this approach had limitations:
# Standard cross-entropy loss
criterion = torch.nn.CrossEntropyLoss(label_smoothing=0.1)Analysis revealed that CE loss optimizes for classification accuracy but doesn’t explicitly optimize for feature discrimination. This creates a “radial” feature space where samples from the same class might not necessarily have high similarity.
Advanced Loss Functions
To address these limitations, I implemented and compared several specialized loss functions:
-
ArcFace Loss: Introduced an angular margin penalty to improve feature discrimination
# ArcFace margin: adding angular separation between classes cos_theta = torch.cos(theta + margin) -
Triplet Loss: Explicitly pushed similar identities closer and dissimilar ones further in feature space
# Triplet loss formulation loss = max(distance(anchor, positive) - distance(anchor, negative) + margin, 0)
The best results came from combining multiple loss components:
# Combined loss approach
total_loss = ce_loss + 0.2 * triplet_lossData Augmentation Strategy
Data augmentation played a critical role in improving model generalization, particularly for the verification task where the model would encounter entirely new identities:
transform_pipeline = Compose([
RandomResizedCrop(size=112, scale=(0.8, 1.0)),
RandomHorizontalFlip(),
ColorJitter(brightness=0.2, contrast=0.2),
RandomRotation(degrees=10),
RandomPerspective(distortion_scale=0.2, p=0.5),
Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])These augmentations helped the model learn to recognize faces under varying conditions:
- RandomResizedCrop: Simulated different face crops and alignments
- RandomHorizontalFlip: Addressed pose variations
- ColorJitter: Improved robustness to lighting and camera differences
- RandomRotation & Perspective: Helped with alignment variations
Verification Pipeline
For the face verification task, I designed a pipeline that leveraged the trained feature extractor:
- Feature Extraction: Pass both face images through the CNN backbone
- Feature Normalization: Normalize the embeddings to unit length
- Similarity Calculation: Compute cosine similarity between the two embeddings
- Threshold Application: Compare similarity score against a threshold
def verify_faces(image1, image2, model, threshold=0.6):
# Extract features
with torch.no_grad():
feat1 = model(image1)["feats"]
feat2 = model(image2)["feats"]
# Normalize features
feat1 = F.normalize(feat1, dim=1)
feat2 = F.normalize(feat2, dim=1)
# Calculate similarity
similarity = F.cosine_similarity(feat1, feat2)
# Return similarity score
return similarity.item()The threshold was determined through validation to optimize the Equal Error Rate (EER), the point where false accept and false reject rates are equal.
Experimental Results
Through systematic experimentation tracked with Weights & Biases, I evaluated different architectures, loss functions, and training strategies:
Classification Performance
| Model Configuration | Train Accuracy | Valid Accuracy | Parameters |
|---|---|---|---|
| ResNet + CE Loss | 95.35% | 89.60% | 27.8M |
| ResNet + ArcFace | 92.81% | 84.38% | 28.1M |
| SE-ResNet + CE | 94.85% | 88.99% | 29.5M |
Verification Performance Analysis
| Model Configuration | EER | TPR@FPR=1e-3 | TPR@FPR=1e-4 |
|---|---|---|---|
| ResNet + CE Loss | 5.3% | 92.1% | 83.2% |
| ResNet + ArcFace | 4.7% | 94.4% | 86.6% |
| SE-ResNet + CE | 3.1% | 97.9% | 89.5% |
The best-performing model achieved an Equal Error Rate (EER) of 3.1%, demonstrating strong verification capabilities even on previously unseen identities.
Key Findings
- Architecture Impact: The addition of Squeeze-and-Excitation blocks improved verification performance by 1.6% EER compared to standard ResNet blocks
- Loss Function Importance: ArcFace loss showed significant improvements for verification tasks compared to standard cross-entropy
- Feature Dimension Trade-offs: 512-dimensional embeddings provided the best balance between accuracy and computational efficiency
- Batch Size Effects: Larger batch sizes (128-256) were crucial for effective training with advanced loss functions
- Learning Rate Scheduling: Step-based learning rate decay yielded better convergence than cosine annealing schedules
Technical Challenges and Solutions
Feature Space Optimization
One of the main challenges was creating a feature space where embeddings from the same identity clustered tightly while maintaining separation between different identities.
Solution: I visualized the learned feature spaces using t-SNE and adjusted margin parameters in the loss functions to find the optimal balance. The final model used a margin of 0.4 in the ArcFace loss component, which provided strong separation without destabilizing training.
Balancing Classification and Verification
Training a model that performed well on both classification (closed-set) and verification (open-set) tasks required careful balancing.
Solution: I implemented a multi-task learning approach where the model was simultaneously optimized for both objectives:
# Multi-task objective
total_loss = (1.0 * classification_loss) + (0.3 * verification_loss)Computational Efficiency
Training deep CNN models with advanced loss functions required significant computational resources.
Solution: I implemented mixed-precision training with automatic mixed precision (AMP) to reduce memory usage and increase training speed:
# Mixed precision training
with torch.cuda.amp.autocast():
outputs = model(images)
loss = criterion(outputs["out"], labels)Conclusion
This project demonstrated the effectiveness of carefully designed CNN architectures and specialized loss functions for face recognition tasks. By understanding the limitations of standard approaches and implementing more advanced techniques, I created a system capable of both accurate classification and robust verification.
The final model achieved strong performance on both tasks:
- 88.99% classification accuracy on the validation set
- 3.1% Equal Error Rate (EER) on the verification task
These results highlight the importance of feature space engineering in face recognition systems and demonstrate how architectural innovations and loss function design can significantly impact performance.
Future Improvements
With additional time and resources, several promising directions emerge:
- Transformer Integration: Incorporating Vision Transformer (ViT) components could enhance the model’s ability to capture long-range dependencies in facial features
- Hard Negative Mining: Implementing more sophisticated sampling strategies to focus on difficult cases
- Ensemble Methods: Combining multiple models with different architectures or loss functions
- Adversarial Training: Improving robustness to variations and potential attacks
Project Links
- GitHub Repository: coming soon…
- Kaggle Competition